Event-Driven Architecture
1. Introduction to Event-Driven Architecture
In the ever-evolving landscape of software architecture, Event-Driven Architecture (EDA) has emerged as a powerful paradigm for building scalable, responsive, and loosely coupled systems. As modern applications face increasing demands for real-time processing, high throughput, and seamless integration, EDA offers a compelling alternative to traditional request-response patterns.
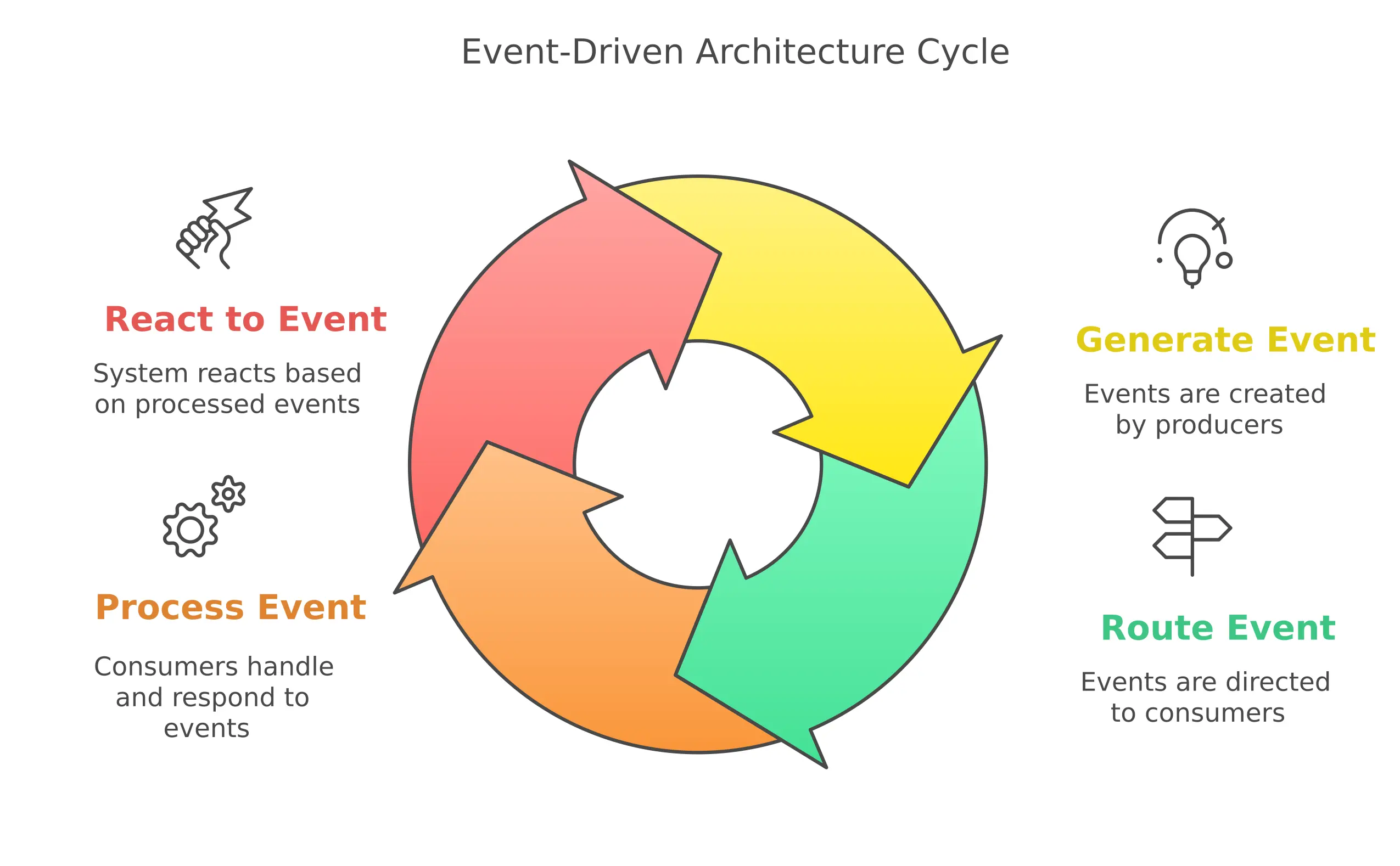
What is EDA?
Event-Driven Architecture is a software design pattern where the flow of the program is determined by events: user actions, sensor outputs, messages from other programs, or services. In EDA, when a significant "happening" (an event) occurs, it's captured, communicated, and processed. The architecture revolves around the production, detection, consumption, and reaction to these events.
Unlike monolithic architectures where components are tightly coupled, EDA facilitates a system where components communicate indirectly through events. An event might represent a customer placing an order, a temperature sensor reading crossing a threshold, or a payment being processed—any meaningful occurrence within the system's domain.
At its core, EDA comprises:
- Event producers - Components that generate events when something notable happens
- Event consumers - Components that listen for and process events
- Event brokers/channels - Middleware that routes events from producers to consumers
Differences from Traditional Request-Driven Systems
Traditional request-driven architectures operate on a synchronous model where a client makes a direct request to a service and waits for a response. This model, while straightforward, introduces several constraints:
| Aspect | Request-Driven Architecture | Event-Driven Architecture |
|---|---|---|
| Communication Pattern | Synchronous, direct | Asynchronous, indirect |
| Coupling | Tight coupling between requestor and responder | Loose coupling between event producers and consumers |
| Dependency | Requires all systems to be available simultaneously | Systems can operate independently |
| Scalability | Limited by the capacity of individual services | Highly scalable with independent producers and consumers |
| Resilience | Failure in one component can block the entire process | Components can fail without bringing down the entire system |
| Flow Control | Client must manage request rates | Natural buffering through event brokers |
In request-driven systems, Service A needs to know about Service B to make a request. If Service B is unavailable or slow, Service A is directly impacted. In contrast, with EDA, Service A emits an event without knowing or caring which services might consume it. Service B can process this event when it's available, and Service A continues its operations unimpeded.
Benefits of Decoupling
The decoupling inherent in event-driven architectures yields numerous advantages:
-
Enhanced Scalability: Components can scale independently based on their specific workload. For instance, if order processing is experiencing high volume, you can scale up just the order processing consumers without affecting other parts of the system.
-
Improved Resilience: A failure in one component doesn't cascade throughout the system. If a payment service is temporarily down, order events can still be produced and queued for processing when the service recovers.
-
Greater Flexibility: New capabilities can be added without modifying existing components. For example, you can add analytics, auditing, or notification features by simply implementing new event consumers without changing the event producers.
-
Natural Load Leveling: Event brokers provide buffering capabilities, allowing the system to handle traffic spikes without overwhelming consumers.
-
Better Real-Time Capabilities: Events are processed as they occur, enabling real-time reactions and updates.
-
Simplified Integration: Services from different teams, departments, or even companies can integrate through event exchange without deep knowledge of each other's internal workings.
-
Support for Polyglot Systems: Different services can be implemented in different programming languages, each optimized for its specific task.
As you delve deeper into EDA, you'll discover how these benefits translate into practical advantages for your specific use cases, whether you're building microservices, IoT applications, real-time analytics systems, or reactive user interfaces.
2. Core Concepts
To effectively work with Event-Driven Architecture, it's essential to understand its fundamental building blocks. These core concepts form the foundation upon which robust and scalable event-driven systems are built.
Event: Definition and Types
An event is a significant occurrence or change in state within a system. It represents something that has happened in the past—a fact that cannot be changed. Events are immutable records of these occurrences, typically containing:
- Event metadata: Unique identifier, timestamp, version, and other administrative information
- Event data: The actual payload describing what happened
Events can be categorized in several ways:
Based on scope:
-
Domain Events: Significant occurrences within a specific business domain. Examples include
OrderPlaced,PaymentReceived, orInventoryAdjusted. These events represent meaningful changes in the domain and often trigger business processes. -
Integration Events: Events that cross domain boundaries and are used for inter-service communication. These events facilitate loose coupling between different parts of a distributed system.
Based on content:
-
Notification Events: Light events that simply announce something has happened without carrying detailed information. Recipients interested in details must request them separately.
-
State Transfer Events: Events that carry the complete state (or a significant portion) of the entity affected by the event.
-
Event-Sourcing Events: Fine-grained events that, when replayed in sequence, can reconstruct the entire state history of an entity.
Based on processing requirements:
- Command Events: Events that represent instructions or commands to be executed.
- Document Events: Events that carry data without necessarily requiring action.
- Stream Events: Continuous series of related events that form a logical stream.
Event Producers: Who Emits Events?
Event producers are the sources of events in the system. They detect or create events and publish them to event channels for consumption. Producers have no knowledge of who will consume their events or what actions will result—they simply announce that something has happened.

Common event producers include:
- User interfaces: Generate events based on user actions (clicks, form submissions, etc.)
- Microservices: Emit events when their internal state changes
- IoT devices: Send events based on sensor readings or state changes
- Databases: Generate events on data changes through change data capture (CDC)
- External systems: Forward events from third-party systems or services
- Scheduled tasks: Create time-based events
Event producers should focus solely on detecting and publishing events without concern for their downstream effects. This separation of responsibilities contributes to the loose coupling that makes EDA powerful.
Event Consumers: Who Reacts to Them?
Event consumers listen for and process events from one or more event channels. Upon receiving an event, a consumer performs actions based on the event's content and type. A single event might trigger multiple consumers, each performing different operations.

Event consumers can:
- Update internal state: Modify their own data or cache based on events
- Trigger workflows: Initiate business processes or workflows
- Transform events: Convert events from one format to another
- Aggregate events: Combine multiple events into higher-level insights
- Forward events: Send transformed events to other channels
- Persist events: Store events for historical analysis or replay
The beauty of EDA is that new consumers can be added without modifying existing components. For example, you could add a new analytics consumer to an existing order processing system without changing the order service itself.
Event Brokers: Middleware like Kafka, RabbitMQ, etc.
Event brokers are specialized middleware that facilitate the reliable delivery of events from producers to consumers. They decouple producers and consumers in both time and space:
- Temporal decoupling: Consumers don't need to be active when events are produced
- Spatial decoupling: Producers and consumers don't need to know each other's locations
Event brokers provide critical services including:
- Event routing: Directing events to interested consumers based on topics, queues, or patterns
- Reliable delivery: Ensuring events aren't lost, even if consumers are temporarily unavailable
- Message persistence: Storing events until they're successfully processed
- Load balancing: Distributing events among multiple consumer instances
- Ordering guarantees: Maintaining the order of related events (when supported)
- Filtering: Allowing consumers to receive only events matching certain criteria
Popular event broker technologies include:

- Apache Kafka: Distributed streaming platform with strong ordering guarantees and high throughput
- RabbitMQ: Feature-rich message broker with flexible routing capabilities
- Amazon SQS/SNS: AWS messaging services for cloud-native applications
- Azure Service Bus/Event Grid: Microsoft's cloud messaging infrastructure
- Google Pub/Sub: Google Cloud's globally distributed message bus
- NATS: Network Addressable Transport System is a lightweight and high-performance messaging system designed for real-time applications and distributed systems
- Redis Streams: Stream processing capabilities built on Redis
The choice of event broker significantly impacts the system's capabilities, scalability, and complexity. Different brokers excel in different scenarios, and some architectures even combine multiple brokers to leverage their respective strengths.
Understanding these core concepts—events, producers, consumers, and brokers—provides the foundation for designing and implementing effective event-driven systems. As you progress through this guide, we'll explore how these elements combine to form powerful architectural patterns.
3. Types of Events
Different types of events serve different purposes within an event-driven system. Understanding these distinctions helps in designing appropriate event schemas and processing mechanisms.
Notification Events vs. State Transfer Events
Events can vary significantly in the amount of information they carry:
Notification Events
Notification events are lightweight events that simply announce that something has happened, without including detailed information about the change. They act as signals that trigger interested parties to take action, often by requesting more information.
Characteristics:
- Minimal payload, usually just an identifier and event type
- Require additional queries to retrieve complete information
- Low bandwidth consumption
- Suitable for high-frequency events
Example:
{
"eventType": "OrderCreated",
"orderId": "12345",
"timestamp": "2023-06-15T14:30:00Z"
}
When a consumer receives this notification, it would need to query the order service to get details about the order, such as items, prices, and customer information.
Use cases:
- Triggering workflows when detailed data isn't immediately needed
- Notifying about changes when data might be large or sensitive
- Systems where consumers need different subsets of the data
State Transfer Events
State transfer events carry comprehensive information about the entity or the change that occurred. They include sufficient data for consumers to process the event without needing to query back to the source system.
Characteristics:
- Rich payload with complete or substantial entity information
- No need for additional queries
- Higher bandwidth consumption
- Facilitates truly decoupled services
Example:
{
"eventType": "OrderCreated",
"orderId": "12345",
"timestamp": "2023-06-15T14:30:00Z",
"customer": {
"id": "C789",
"name": "Alice Johnson",
"email": "alice@example.com"
},
"items": [
{
"productId": "P101",
"name": "Wireless Headphones",
"quantity": 1,
"unitPrice": 79.99
},
{
"productId": "P205",
"name": "Phone Case",
"quantity": 2,
"unitPrice": 19.99
}
],
"totalAmount": 119.97,
"shippingAddress": {
"street": "123 Main St",
"city": "Boston",
"state": "MA",
"zipCode": "02108"
},
"paymentMethod": "credit_card"
}
Use cases:
- When consumers need complete information to perform their tasks
- In systems where the source might not be available when events are processed
- Data replication and synchronization between services
The choice between notification and state transfer events involves trade-offs:
| Factor | Notification Events | State Transfer Events |
|---|---|---|
| Network Bandwidth | Lower | Higher |
| Source System Load | Higher (due to follow-up queries) | Lower (no additional queries) |
| Consumer Autonomy | Lower (depends on source availability) | Higher (self-contained) |
| Data Consistency | Better (always gets latest data) | Potential for staleness |
| Complexity | Higher (requires query mechanism) | Lower (everything in one event) |
Many systems use a hybrid approach, with notification events for high-frequency, low-priority changes and state transfer events for critical updates.
Domain Events vs. Integration Events
Another important distinction is based on the scope and boundary of events:
Domain Events
Domain events represent significant occurrences within a specific bounded context or domain. They are closely tied to the domain model and business rules of a particular service or component.
Characteristics:
- Express domain-specific concepts and language
- Often fine-grained and detailed
- Typically consumed within the same domain
- Represent business-meaningful occurrences
Example:
{
"eventType": "LoanApplicationApproved",
"loanApplicationId": "LA-2023-06-15-0042",
"approvedBy": "underwriter-218",
"approvalDate": "2023-06-15T16:42:00Z",
"approvedAmount": 250000.00,
"loanTermMonths": 360,
"interestRate": 4.25,
"riskScore": 720
}
Use cases:
- Triggering domain-specific business rules and workflows
- Maintaining consistency within a bounded context
- Supporting event sourcing within a domain
Integration Events
Integration events facilitate communication across domain boundaries. They represent facts that other domains or external systems need to know about, often translated from domain events into a more universally understood format.
Characteristics:
- Designed for cross-domain or external consumption
- More coarse-grained than domain events
- Stable contracts that change less frequently
- Often represent completed business processes
Example:
{
"eventType": "MortgageApproved",
"applicationId": "LA-2023-06-15-0042",
"customerId": "C123456",
"propertyAddress": {
"street": "456 Oak Avenue",
"city": "Seattle",
"state": "WA",
"zipCode": "98101"
},
"approvalDate": "2023-06-15T16:42:00Z",
"loanAmount": 250000.00,
"closingDate": "2023-07-20T00:00:00Z"
}
Note how this integration event is derived from the domain event but exposes only what other systems need to know, using more general terminology and hiding internal details.
Use cases:
- Cross-domain communication
- Integration with external systems
- Building composite views across domains
| Aspect | Domain Events | Integration Events |
|---|---|---|
| Scope | Within a bounded context or domain | Across multiple domains or external systems |
| Purpose | Represent domain-specific business occurrences | Communicate significant events to other systems or services |
| Granularity | Fine-grained and detailed | Coarse-grained and abstracted |
| Language | Uses domain-specific terminology | Uses general or shared terminology |
| Consumers | Consumed within the same domain | Consumed across domain boundaries or by external services |
| Change Frequency | Can change frequently with business logic | More stable contracts to reduce integration impact |
| Payload | Includes internal details relevant to domain logic | Includes only necessary information for external consumers |
| Use Cases | Trigger business rules, workflows, event sourcing within the domain | Cross-domain communication, external integration, composite views |
| Ownership | Owned and evolved by the domain team | Requires coordination with external consumers to manage contracts |
Understanding the differences between these event types helps in designing appropriate event schemas and determining the right level of detail and scope for each event. As systems grow in complexity, having a clear taxonomy of events becomes increasingly important for maintaining clarity and avoiding confusion about the purpose and handling of different events.
4. Communication Models
Event-driven architectures support several communication models, each with unique characteristics suitable for different scenarios. Understanding these models helps architects choose the right approach for their specific requirements.

1. Publish/Subscribe
The Publish/Subscribe (Pub/Sub) pattern is a cornerstone of event-driven architectures. In this model:
- Publishers (event producers) emit events to a topic or channel without knowing who will receive them
- Subscribers (event consumers) express interest in topics and receive events from those topics
- A broker manages the distribution of events from publishers to relevant subscribers

Key characteristics of Pub/Sub:
a. Many-to-many communication: Multiple publishers can send to a topic, and multiple subscribers can receive from it.
b. Topic-based routing: Events are routed based on their topic or category.
c. Dynamic subscription management: Subscribers can join or leave at any time.
Implementation Approaches:
-
Topic-based Pub/Sub: Subscribers receive all events published to the topics they subscribe to
Publisher → Topic A → Subscriber 1, Subscriber 2
Publisher → Topic B → Subscriber 2, Subscriber 3 -
Content-based Pub/Sub: Events are filtered based on their content or attributes
Publisher → [Filter: priority="high"] → Subscriber 1
Publisher → [Filter: type="payment"] → Subscriber 2 -
Hierarchical Pub/Sub: Topics are organized in a hierarchy, and subscribers can subscribe to entire subtrees
Publisher → orders.placed → Subscriber to "orders.*"
Publisher → orders.shipped → Subscriber to "orders.*"
Use Cases:
- Broadcasting notifications to multiple interested services
- Enabling extensibility where new subscribers can be added without modifying publishers
- Implementing fan-out patterns where one event triggers multiple processes
Popular Technologies:
- Apache Kafka (for high-throughput, persistent pub/sub)
- RabbitMQ with exchanges
- AWS SNS (Simple Notification Service)
- Google Cloud Pub/Sub
- Azure Event Grid
2. Event Streaming
Event streaming extends the pub/sub model with the concept of a durable, ordered log of events that can be replayed. Rather than treating events as transient messages, event streaming platforms maintain events as records in a persistent log.
Key characteristics of Event Streaming:
- Persistence: Events are stored in an ordered log, often with configurable retention periods
- Replayability: Consumers can re-read historical events from any point
- Order preservation: Events maintain their sequential order within a partition
- Scalable consumption: Multiple consumer groups can process the same stream independently

Implementation Approaches:
-
Partitioned Streams: Events are divided across multiple partitions for parallel processing
Publisher → Partition 0 → Consumer Group A (Instance 1)
Publisher → Partition 1 → Consumer Group A (Instance 2)
Publisher → Partition 0 → Consumer Group B (Instance 1) -
Offset-based Consumption: Consumers track their position (offset) in each stream
Stream: [Event 0] [Event 1] [Event 2] [Event 3] [Event 4]
Consumer A position: ---------------^
Consumer B position: --------------------------^
Use Cases:
- Building event sourcing systems
- Real-time data pipelines and analytics
- Processing chronological events in order
- Creating derived views and materialized caches
- Implementing command and event sourcing patterns
Popular Technologies:
- Apache Kafka
- AWS Kinesis
- Azure Event Hubs
- Redis Streams
- Apache Pulsar
3. Message Queues
Message queues provide point-to-point communication between producers and consumers, with messages typically processed exactly once by a single consumer.
Key characteristics of Message Queues:
- Delivery guarantees: Messages are typically delivered to exactly one consumer
- Load balancing: Work is distributed among multiple consumer instances
- Buffering: Queues provide temporary storage when consumers are slower than producers
- Back-pressure management: Queues can enforce limits to prevent overwhelming consumers

Implementation Approaches:
-
Simple Queues: Messages are consumed in roughly the order they were produced
Producer → [Queue] → Consumer -
Priority Queues: Messages with higher priority are processed before lower priority ones
Producer → [Priority Queue] → Consumer (gets high priority first) -
Competing Consumers: Multiple instances consume from the same queue for scalability
Producer → [Queue] → Consumer 1, Consumer 2, Consumer 3
Use Cases:
- Work distribution and load balancing
- Implementing the command pattern
- Background job processing
- Ensuring ordered processing by a single consumer
- Controlling the rate of processing
Popular Technologies:
- RabbitMQ
- AWS SQS (Simple Queue Service)
- Azure Service Bus
- ActiveMQ
- ZeroMQ
4. Comparison of Communication Models
| Aspect | Publish/Subscribe | Event Streaming | Message Queues |
|---|---|---|---|
| Communication Pattern | One-to-many | Many-to-many with history | One-to-one |
| Event Persistence | Typically transient | Persistent log | Typically transient until processed |
| Consumption Model | Broadcast to all subscribers | Independent consumer groups | Single consumer per message |
| Ordering Guarantees | Varies by implementation | Strong (within partitions) | Usually FIFO |
| Scalability Approach | Multiple subscribers | Partitioning | Competing consumers |
| Replay Capability | Limited | Comprehensive | Usually none |
| Common Use Case | Notifications, fan-out | Event sourcing, analytics | Work distribution, commands |
Many complex event-driven architectures combine these models, using:
- Pub/Sub for broadcasting events to interested services
- Event Streaming for durable event logs and replay capabilities
- Message Queues for reliable work distribution and processing
The choice of communication model significantly impacts the system's behavior, particularly regarding scalability, reliability, and message delivery semantics. Architects should carefully consider these characteristics when designing event-driven systems.
5. EDA Components and Architecture
A comprehensive Event-Driven Architecture consists of several integrated components that work together to enable the flow of events through the system. Understanding these components and their interactions is crucial for designing robust and scalable event-driven systems.
Event Source (e.g., service, UI)
Event sources are the origin points where events are first detected and captured. These components identify when something significant has occurred and translate that occurrence into an event object or message.
Types of Event Sources:
-
Application Services: Microservices or applications that generate events when their internal state changes or when they perform important operations.
-
User Interfaces: Web applications, mobile apps, or other UIs that produce events based on user actions (clicks, form submissions, navigation).
-
IoT Devices: Sensors, machines, and other connected devices that generate events based on environmental changes or operational states.
-
Databases: Through Change Data Capture (CDC), databases can emit events when data is created, updated, or deleted.
-
External Systems: Third-party applications, legacy systems, or partner services that generate events consumed by your system.
-
Scheduled Processes: Jobs that run at specific times and generate events (e.g., daily reconciliation, periodic health checks).
Responsibilities of Event Sources:
- Event Detection: Identifying when a relevant state change or action has occurred
- Event Creation: Constructing proper event objects with required metadata and payload
- Event Validation: Ensuring events conform to the expected schema and business rules
- Event Publication: Sending events to the appropriate channel or broker
Event Channel or Broker
The event channel or broker is the messaging infrastructure that facilitates the transportation of events from producers to consumers. This component is critical for achieving the decoupling that makes event-driven architectures so powerful.
Functions of Event Brokers:
- Message Transport: Moving events from producers to consumers reliably
- Temporary Storage: Buffering events when consumers are unavailable or processing slowly
- Routing Logic: Directing events to the appropriate consumers based on topics, patterns, or content
- Delivery Guarantees: Ensuring events are delivered with the desired semantics (at-least-once, at-most-once, or exactly-once)
- Scaling Support: Distributing load across multiple broker instances
- Monitoring and Management: Providing visibility into message flow and system health
Common Broker Topologies:
-
Centralized Broker: All producers and consumers connect to a single logical broker
Producer A → [Central Broker] → Consumer X
Producer B → [Central Broker] → Consumer Y -
Federated Brokers: Multiple broker instances that share information
Producer A → [Broker 1] ⟷ [Broker 2] → Consumer X
Producer B → [Broker 2] → Consumer Y -
Clustered Brokers: Multiple instances forming a single logical broker for high availability
Producer A → [Broker Cluster] → Consumer X
Producer B → [Broker Cluster] → Consumer Y
Event Processor/Handler
Event processors or handlers are components that receive, interpret, and act on events. They embody the business logic that reacts to events occurring in the system.
Responsibilities of Event Processors:
- Event Reception: Subscribing to relevant event channels and receiving events
- Event Deserialization: Converting the transport format into domain objects
- Event Validation: Verifying that events are valid and can be processed
- Business Logic Execution: Performing the actual work in response to events
- Side Effects Management: Handling database updates, external API calls, etc.
- Error Handling: Managing failures and retries
- Event Production: Optionally generating new events as a result of processing
Implementation Patterns:
- Synchronous Handlers: Process events in the main application thread
- Asynchronous Handlers: Process events in background threads or workers
- Stateless Handlers: Maintain no state between event processing
- Stateful Handlers: Maintain state to correlate or aggregate related events
- Idempotent Handlers: Safely handle duplicate event deliveries without unwanted side effects
Event Store (if using Event Sourcing)
For architectures implementing the Event Sourcing pattern, an event store is a specialized database that persists the complete history of events. It serves as the authoritative record of all changes in the system.
Characteristics of Event Stores:
- Append-Only: Events are only added, never modified or deleted
- Sequential Storage: Events are stored in chronological order
- Versioning Support: Events often include version information for consistency checks
- Snapshot Capability: Many event stores support snapshots for performance optimization
- Subscription API: Allows components to subscribe to new events as they're appended
Functions of Event Stores:
- Event Persistence: Storing events durably with guaranteed order
- Event Retrieval: Fetching events by aggregate ID, time range, or other criteria
- Current State Computation: Some stores help rebuild current state from event sequences
- Subscription Management: Supporting real-time notifications of new events
- Optimization Features: Snapshots, caching, and indexing to improve performance
Sample EDA Component Interactions
To illustrate how these components interact in a typical event-driven architecture, consider this e-commerce order processing flow:
-
User places an order (Event Source)
- The UI captures the order details and creates an
OrderPlacedevent - Event is published to the broker
- The UI captures the order details and creates an
-
Order Service processes the order (Event Processor)
- Subscribes to
OrderPlacedevents - Validates the order, checks inventory
- Updates its database (or event store)
- Publishes an
OrderValidatedevent
- Subscribes to
-
Payment Service processes payment (Event Processor)
- Subscribes to
OrderValidatedevents - Processes payment through a payment gateway
- Publishes a
PaymentProcessedevent
- Subscribes to
-
Inventory Service updates stock (Event Processor)
- Subscribes to
PaymentProcessedevents - Updates inventory levels
- Publishes an
InventoryUpdatedevent
- Subscribes to
-
Shipping Service prepares shipment (Event Processor)
- Subscribes to
PaymentProcessedevents - Creates a shipping label
- Schedules pickup
- Publishes a
ShipmentCreatedevent
- Subscribes to
-
Notification Service informs customer (Event Processor)
- Subscribes to various events in the order flow
- Sends appropriate emails to the customer at each stage
This example demonstrates how events flow through the system, with each component performing its specific role while remaining decoupled from others. The event broker ensures reliable delivery between these components, even if some services are temporarily unavailable.
Architectural Considerations
When designing an event-driven architecture, several factors should be considered:
- Granularity of Events: Too fine-grained events may lead to excessive messaging overhead, while too coarse-grained events might limit flexibility
- Event Ownership: Clearly define which services own and can emit which events
- Schema Evolution: Plan for how event schemas will evolve over time
- Transactionality: Determine how to handle transactions that span multiple event processors
- Eventual Consistency: Design systems to handle temporary inconsistencies between services
- Fault Tolerance: Implement strategies for handling failures at various points in the event flow
- Monitoring and Debugging: Establish comprehensive observability into the event flow
6. Tools & Technologies
Modern event-driven architecture (EDA) requires robust infrastructure to handle events at scale. As organizations increase their event volumes and processing requirements, they must select appropriate tools that provide reliability, scalability, and performance.
Messaging Systems
Messaging systems form the backbone of event-driven architectures by providing reliable event delivery mechanisms:
Apache Kafka has become the de facto standard for high-throughput event streaming. Its distributed architecture provides horizontal scalability, fault tolerance through replication, and strong ordering guarantees within partitions. Kafka excels at handling millions of events per second and retaining data for extended periods. It's particularly valuable for large-scale data pipelines, where its ability to replay events from storage provides data recovery capabilities.
RabbitMQ offers a more traditional message broker approach with strong delivery guarantees and flexible routing capabilities. Its exchange-based routing system permits complex message distribution patterns including fanout, direct, and topic-based routing. RabbitMQ handles lower throughput than Kafka but excels at reliable delivery and complex routing scenarios.
AWS SNS/SQS provides managed messaging services in the AWS ecosystem. Simple Notification Service (SNS) delivers messages to multiple subscribers using a publish-subscribe model, while Simple Queue Service (SQS) offers point-to-point queuing with strong delivery guarantees. These services integrate seamlessly with other AWS offerings, making them ideal for AWS-based architectures.
Azure Event Grid enables event-based applications in the Microsoft cloud. It's designed for reactive programming patterns and enables filtering and routing events across Azure services and beyond. Event Grid's primary strength is its deep integration with Azure services and its ability to handle platform events.
NATS focuses on simplicity and performance, providing lightweight message delivery with minimal overhead. Its newer JetStream persistence layer adds the ability to store and replay messages. NATS shines in low-latency scenarios where performance trumps feature richness.
Streaming Platforms
While messaging systems handle individual events, streaming platforms process continuous flows of data:
Apache Pulsar combines messaging and streaming capabilities, offering multi-tenant architecture with strong isolation. Pulsar separates compute from storage, enabling independent scaling of brokers and bookkeepers. Its tiered storage approach automatically moves older data to cost-effective storage while maintaining accessibility.
Redis Streams leverages Redis's in-memory performance for stream processing, making it suitable for real-time analytics on ephemeral data. While not as robust as dedicated streaming platforms for persistent workloads, Redis Streams provides exceptional performance for time-sensitive use cases.
Webhooks vs Message Queues
Webhooks provide HTTP callbacks that trigger when events occur, pushing data directly to subscribers. They're simple to implement and require minimal infrastructure but lack durability and retry mechanisms. Webhooks work well for integrations where simplicity and immediate notification are prioritized over guaranteed delivery.
Message Queues offer stronger delivery guarantees through persistence and decoupling of producers and consumers. They handle consumer downtime gracefully by queuing messages until consumers can process them and typically offer retry mechanisms for failed deliveries. Message queues excel where reliable delivery is critical, even at the cost of increased latency.
7. Design Patterns in EDA
Different event patterns address various architectural needs:
Event Notification
The simplest pattern, event notification simply signals that something happened without including comprehensive data. For example, a notification might indicate "Order #12345 was placed" without including order details. Consumers interested in details must query the source system for complete information.
Benefits: Lightweight events, reduced network traffic, clear separation of concerns Drawbacks: Requires additional queries, can increase system coupling, potentially inconsistent data
Event-Carried State Transfer
This pattern embeds relevant state information within the event itself. Following our previous example, an event-carried state transfer message would include all order details like customer information, items ordered, and pricing. Consumers receive complete information without additional queries.
Benefits: Reduces network round-trips, improves consumer independence, provides historical context Drawbacks: Larger event size, potential information duplication, versioning challenges
Event Sourcing
Event sourcing stores every state change as an immutable event record. The current state of entities is derived by replaying all events from the beginning. This creates a complete audit trail and enables temporal queries (what was the state at a specific point in time?).
Benefits: Complete auditability, temporal queries, simplified debugging Drawbacks: Complexity in event schema evolution, potential performance overhead, learning curve
Command Query Responsibility Segregation (CQRS)
CQRS separates operations that modify state (commands) from operations that read state (queries). This allows each side to be optimized independently—write models can focus on consistency and validation, while read models can be denormalized for query performance.
Benefits: Performance optimization, scalability, flexible data representation Drawbacks: Increased complexity, eventual consistency challenges, duplicate data storage
8. Event Modeling & Schema Design
Well-designed event schemas ensure interoperability and system evolution:

Event Contracts
Event contracts formalize the structure and semantics of events:
Apache Avro provides compact binary serialization with built-in schema evolution. Its schema resolution rules enable consumers to read data produced with newer or older schemas, facilitating compatibility across versions.
JSON Schema offers a readable, human-friendly approach to schema definition. While not as compact as binary formats, JSON Schema is widely supported and easier to debug.
Protocol Buffers (Protobuf) from Google provides efficient binary serialization with strong typing. Its interface definition language explicitly defines message structures, ensuring consistent interpretation across languages.
Versioning Events
As systems evolve, event schemas must change. Effective versioning strategies include:
- Forward compatibility: New consumers can read old events
- Backward compatibility: Old consumers can read new events
- Schema registries: Central repositories that store and validate schemas
Best practices include:
- Only adding optional fields, never removing fields
- Providing default values for new fields
- Including version identifiers in event metadata
- Maintaining compatibility for a reasonable transition period
Event Naming Conventions
Clear naming improves system understanding and maintenance:
- Use past tense verbs for events (UserCreated, OrderShipped)
- Include the domain entity in the name
- Be specific yet concise
- Maintain consistent naming patterns across the organization
9. Error Handling and Retry Strategies
Resilient event processing requires robust error management:
Dead Letter Queues (DLQ)
When an event can't be processed after multiple attempts, it's moved to a dead letter queue for separate handling. DLQs prevent problematic events from blocking the processing pipeline while preserving them for analysis and potential reprocessing.
Effective DLQ strategies include:
- Automatic alerts when events enter the DLQ
- Tools for inspecting and reprocessing dead-lettered events
- Monitoring of DLQ size and growth rates
- Periodic review of consistently failing events
Idempotency
Idempotent operations produce the same result regardless of how many times they're executed. In event processing, idempotency ensures that duplicate events don't cause incorrect state changes. Techniques for achieving idempotency include:
- Tracking processed event IDs to detect duplicates
- Using natural idempotency where possible (e.g., setting a value rather than incrementing)
- Designing operations to be safely repeatable
- Implementing idempotency tokens for multi-step processes
Delivery Guarantees
Different messaging systems offer varying delivery guarantees:
- At-least-once: Messages are guaranteed to be delivered, but might be delivered multiple times. Consumers must handle duplicates.
- At-most-once: Messages are delivered once or not at all. Simple but can result in message loss.
- Exactly-once: The holy grail of delivery semantics, ensuring messages are processed exactly once. Often achieved through a combination of at-least-once delivery with idempotent processing.
System requirements dictate the appropriate guarantee level. Financial systems typically require exactly-once semantics, while monitoring systems might tolerate at-least-once delivery.
10. Reliability and Scalability
Event-driven architectures must maintain reliability under varying load:
Horizontal Scaling
EDA naturally supports horizontal scaling by:
- Partitioning event streams across multiple consumers
- Adding consumer instances to increase processing capacity
- Distributing broker responsibilities across server clusters
For example, Kafka's consumer groups automatically rebalance workloads when consumers join or leave, maintaining processing efficiency.
Event Replay
The ability to replay events provides powerful recovery and reprocessing capabilities:
- System recovery after failures
- Rebuilding corrupted data stores
- Testing new processing logic against historical data
- Creating new views or aggregates from the event history
Distributed Systems Considerations
Event-driven architectures must address distributed systems challenges:
- Partitioning: Dividing event streams for parallel processing
- Latency: Managing variable processing and network delays
- Consistency: Balancing immediate visibility with correctness
- Network partitions: Handling temporary communication failures
11. EDA in Microservices
Events enable loosely coupled microservice architectures:
Decoupling Microservices
Traditional microservice architectures often rely on synchronous HTTP calls, creating tight coupling and potential failure cascades. Event-driven microservices communicate asynchronously, reducing interdependencies:
- Services publish events without knowing who will consume them
- Consumers process events independently, at their own pace
- New services can be added without modifying existing components
- Services can evolve independently as long as event contracts remain stable
Saga Pattern
Long-running business processes spanning multiple services require coordination without distributed transactions. The saga pattern orchestrates these processes through events:
Choreographed sagas use events to trigger the next step in the process. Each service publishes events indicating completion of its part, which other services listen for to trigger their actions. This approach is decentralized but can be difficult to monitor.
Orchestrated sagas use a central coordinator to manage the process flow. The coordinator sends commands to services and tracks their completion, handling failures and compensating actions. This approach provides better visibility and control but creates a potential single point of failure.

Explanation of the Saga Pattern Sequence Diagram:
A. Client : Initiates a distributed transaction.
B. ServiceA, ServiceB, ServiceC : Independent services participating in the distributed transaction.
C. Saga Coordinator : Orchestrates the saga, managing the sequence of transactions and compensating transactions.
12. Monitoring and Observability
Asynchronous systems require specialized monitoring approaches:
Tracing Events
Distributed tracing follows events as they flow through the system:
- Jaeger and Zipkin provide end-to-end visibility into request flows
- Correlation IDs link related events across services
- Span collection captures timing information for performance analysis
Effective tracing requires:
- Propagating trace context through event metadata
- Consistent instrumentation across services
- Sampling strategies for high-volume systems
Logs and Metrics
Operational visibility relies on comprehensive instrumentation:
- Prometheus for time-series metrics and alerting
- Grafana for visualization and dashboarding
- ELK Stack for log aggregation and search
Key metrics to monitor include:
- Message throughput and latency
- Processing errors and retries
- Queue depths and growth rates
- Consumer lag indicators
13. Event Sourcing (Advanced Topic)
Event sourcing captures all state changes as an immutable event log:
Storing Events
Event stores must provide:
- Append-only operation to maintain immutability
- Efficient retrieval by entity ID or time range
- Optimized storage for long-term retention
- Consistency guarantees for event sequences
Rebuilding State
Current state is reconstructed by:
- Replaying all events for an entity
- Applying events in sequence to compute current state
- Optionally creating snapshots for performance optimization
- Supporting temporal queries at specific points in time
Challenges
Event sourcing introduces complexities:
- Schema evolution requires careful management
- Performance considerations for high-cardinality entities
- Projection management for derived views
- Learning curve for developers accustomed to CRUD operations
14. Real-World Use Cases
Event-driven architecture powers numerous domains:
E-commerce
Online retail leverages EDA for:
- Real-time inventory updates across channels
- Order processing workflows
- Customer notifications
- Price and promotion adjustments
- Recommendation engine feeds
IoT
Connected devices generate streams of events:
- Sensor data processing and aggregation
- Anomaly detection and alerting
- Device provisioning and management
- Firmware update coordination
- Usage pattern analysis
Fraud Detection
Financial systems use events to identify suspicious activity:
- Real-time transaction monitoring
- Behavior pattern analysis
- Rule-based alert generation
- Machine learning model inputs
- Cross-channel activity correlation
Analytics
Real-time business intelligence relies on event streams:
- Key performance indicator dashboards
- Customer behavior analysis
- A/B test result processing
- Marketing campaign effectiveness tracking
- Operational metrics visualization
15. Challenges & Pitfalls
EDA introduces specific challenges that require careful management:
Event Ordering
Maintaining proper event sequence is crucial but difficult:
- Network delays can reorder messages
- Distributed clocks create timestamp inconsistencies
- Partitioned systems process events in parallel
Solutions include:
- Logical timestamps (Lamport clocks)
- Causality tracking through event metadata
- Enforcing ordering within critical sequences
Duplicate Processing
Events may be delivered multiple times due to:
- Retry mechanisms after failures
- Distribution system guarantees
- Producer resubmissions
Mitigation strategies include:
- Designing idempotent handlers
- Tracking processed event IDs
- Using natural idempotency where possible
Debugging
Asynchronous flows complicate troubleshooting:
- Events may be processed long after creation
- Cause-effect relationships span multiple systems
- Error sources may be distant from symptoms
Improving debuggability requires:
- Comprehensive distributed tracing
- Correlation IDs linking related events
- Detailed logging with context
- Replay capabilities for reproducing issues
Eventual Consistency
EDA typically operates under eventual consistency models:
- Different views may temporarily show inconsistent states
- Queries may return stale data during propagation
- Processing delays create visibility gaps
Managing these challenges requires:
- Setting appropriate expectations with stakeholders
- Designing UIs to handle inconsistency gracefully
- Providing indicators of data freshness
- Implementing compensation mechanisms for critical inconsistencies
By understanding these tools, patterns, and challenges, organizations can implement event-driven architectures that provide scalability, resilience, and responsiveness while avoiding common pitfalls that undermine system reliability.
Conclusion
Event-Driven Architecture represents a paradigm shift in how systems are designed, built, and operated. By embracing asynchronous, event-based communication, organizations can create more resilient, scalable, and adaptable systems that better align with the unpredictable nature of modern business environments.
The key strengths of EDA include:
- Decoupling of components, allowing independently evolving services
- Scalability through horizontally distributed processing
- Resilience via buffering and retry mechanisms
- Flexibility to add new capabilities without disrupting existing ones
- Temporal value in the form of event histories and replay capabilities
However, implementing EDA successfully requires careful consideration of:
- Tool selection appropriate to specific use cases and requirements
- Well-designed event schemas with clear versioning strategies
- Robust error handling and idempotent processing
- Comprehensive monitoring and observability solutions
- Addressing the complexities of distributed systems
As organizations continue their digital transformation journeys, event-driven architecture will increasingly serve as a foundational approach for building systems that can adapt to changing business needs, scale efficiently, and deliver real-time capabilities. The technology ecosystem supporting EDA continues to mature, with increasingly sophisticated tooling making implementation more accessible across industries.
The true power of event-driven architecture emerges when it's applied as part of a thoughtful, domain-driven design approach that models business processes as events flowing through the system. When business stakeholders can recognize their domain language and processes in the event streams, technology becomes a natural extension of business operations rather than a separate concern.
Ultimately, EDA is not merely a technical architecture but a strategic approach to building systems that can evolve with the organization, capture valuable historical context, and respond to the increasing need for real-time processing in our connected world.