Scalability and Load Balancing in Software Architecture
1. Introduction
In today's digital landscape, applications must handle increasing loads while maintaining performance and reliability. Whether you're developing a startup's minimum viable product or managing enterprise-level systems, understanding scalability and load balancing is crucial for creating resilient software architectures. This comprehensive guide explores these fundamental concepts, their implementation strategies, challenges, and future trends.
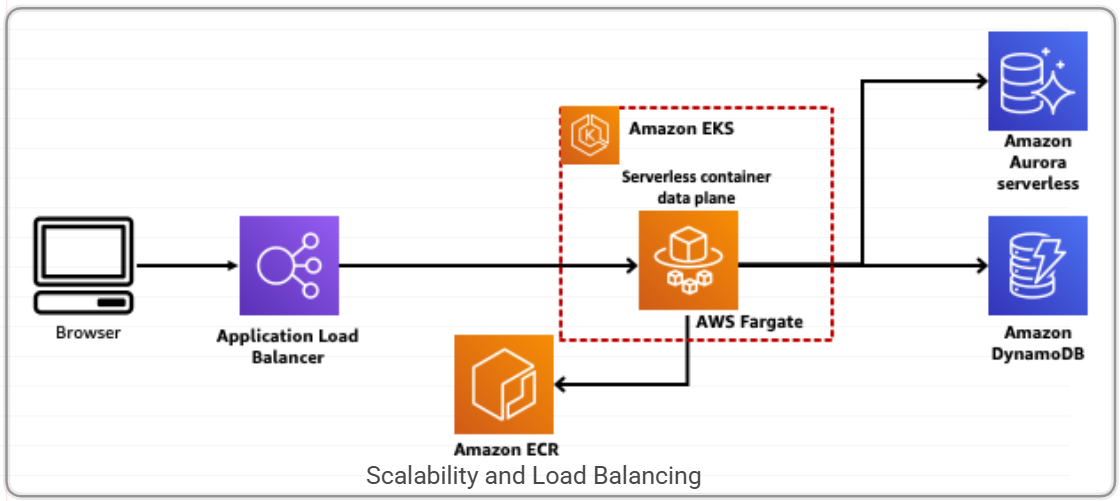
2. Understanding Scalability
2.1 Definition and Importance
Scalability is a system's ability to handle growing workloads by adding resources to the system. A scalable architecture accommodates growth without sacrificing performance or requiring complete redesign. In today's rapidly evolving technological environment, scalability isn't just a nice-to-have—it's essential.
 Why scalability matters:
Why scalability matters:
- User Experience: Slow response times due to system overload can drive users away
- Business Continuity: Systems that can't scale with demand risk downtime during peak usage
- Cost Efficiency: Well-designed scalable systems optimize resource utilization
- Future-Proofing: Scalable architectures adapt to evolving business requirements
2.2 Types of Scalability
A. Vertical Scaling (Scaling Up)
Vertical scaling involves adding more power to existing machines by increasing CPU, RAM, storage, or other resources. Imagine upgrading your server from 8GB to 32GB of RAM, or from a 4-core to a 16-core processor.

Advantages:
- Simple to implement—just upgrade hardware
- No application architecture changes required
- Reduces network overhead
- Often easier to maintain
Limitations:
- Hardware has physical constraints
- Cost increases non-linearly with capacity
- Single point of failure concerns
- Potential downtime during upgrades
When to use vertical scaling:
- Simple applications with moderate growth projections
- Applications with tight data coupling requirements
- When simplicity of management is prioritized
- For specialized hardware requirements (e.g., GPU-intensive applications)
B. Horizontal Scaling (Scaling Out)
Horizontal scaling distributes workload across multiple machines, adding more instances rather than making existing ones more powerful. Think adding ten more servers to your cluster instead of upgrading one.

Advantages:
- Virtually unlimited scaling potential
- Better fault tolerance through redundancy
- More cost-effective for large-scale systems
- No downtime needed for capacity increases
Limitations:
- More complex architecture
- Requires stateless design or sophisticated state management
- Network overhead increases
- Data consistency can be challenging
When to use horizontal scaling:
- Web applications with variable traffic patterns
- Microservices architectures
- Applications requiring high availability
- When cost optimization at scale is critical
C. Diagonal Scaling (Hybrid Approach)
Many modern systems employ diagonal scaling—combining both approaches by adding more machines (horizontal) and upgrading existing ones (vertical) as needed.
2.3 Scalability Patterns and Principles
A. Statelessness
Stateless applications don't store client session data between requests, making horizontal scaling much simpler. Each request contains all information needed for processing, allowing any available server to handle it.
B. Database Scaling Strategies
Databases often become bottlenecks in scaling. Common strategies include:
- Replication: Creating read replicas to distribute query load
- Sharding: Partitioning data across multiple database instances
- NoSQL solutions: Using databases designed for horizontal scalability
- Polyglot persistence: Using different database types for different data needs
C. Caching
Caching stores frequently accessed data in fast-access storage, reducing computational load and database queries:
- Client-side caching: Browsers storing assets and data
- CDN caching: Distributing static content geographically
- Application caching: In-memory stores like Redis or Memcached
- Database caching: Query results and computed values
D. Asynchronous Processing
Decoupling time-intensive operations from the request-response cycle improves scalability:
- Message queues: RabbitMQ, Kafka, SQS for task distribution
- Background jobs: Processing heavy tasks separately
- Event-driven architecture: Responding to events rather than synchronous calls
3. Load Balancing Fundamentals
3.1 Definition and Purpose
Load balancing distributes incoming network traffic or workloads across multiple servers or computing resources. This critical component enables horizontal scaling by ensuring no single server bears too much burden.
Key benefits of load balancing:
- Improved Availability: Continues operating despite server failures
- Optimized Resource Usage: Prevents individual server overload
- Scalability Support: Facilitates adding or removing resources based on demand
- Performance Enhancement: Reduces response times through efficient resource allocation
3.2 Load Balancing Algorithms
A. Round Robin
The simplest algorithm—requests are distributed sequentially across server pool. Server 1 gets request 1, server 2 gets request 2, and so on, cycling back to the beginning after reaching the last server.
Advantages:
- Simple implementation
- Equal distribution if servers have identical capacity
- Works well with homogeneous environments
Limitations:
- Doesn't account for varying server capabilities
- No consideration for connection persistence
- Can't adjust for actual server load
B. Least Connection
Directs traffic to servers with the fewest active connections, assuming fewer connections mean more available capacity.
Advantages:
- Better handling of varying connection durations
- Adapts to server load imbalances over time
- Prevents overloading busy servers
Limitations:
- Connection count isn't always proportional to resource usage
- Additional overhead to track connection counts
- Still doesn't consider server processing capabilities
C. Weighted Algorithms
Variants of other algorithms that assign importance factors to servers based on their capacity or performance:
- Weighted Round Robin: High-capacity servers receive proportionally more requests
- Weighted Least Connection: Server capacity influences connection distribution
Advantages:
- Accommodates heterogeneous server environments
- Can be tuned based on known server capabilities
- Balances efficiency with implementation simplicity
Limitations:
- Requires manual configuration of weights
- Doesn't automatically adapt to changing conditions
- Still somewhat static in nature
D. IP Hash
Uses the client's IP address to determine which server receives the request, ensuring the same client consistently connects to the same server.
Advantages:
- Session persistence without cookies or shared storage
- Useful for applications requiring sticky sessions
- Distributes load predictably
Limitations:
- Uneven distribution with certain IP patterns
- Problems with NAT scenarios (many clients share one IP)
- Can't easily adapt to varying server loads
E. Least Response Time
Routes requests to the server with the lowest combination of active connections and response time.
Advantages:
- Accounts for both server load and performance
- Adapts to varying processing capabilities
- Optimizes for end-user experience
Limitations:
- More complex to implement
- Overhead of monitoring response times
- Potentially sensitive to temporary fluctuations
3.3 Load Balancer Types
A. Hardware Load Balancers
Purpose-built physical devices dedicated to load balancing:
Advantages:
- High performance and throughput
- Hardware acceleration for SSL/TLS termination
- Low latency
- Often include specialized security features
Limitations:
- Expensive initial investment
- Physical scaling limitations
- Vendor lock-in concerns
- Requires physical management and maintenance
Examples: F5 BIG-IP, Citrix ADC (formerly NetScaler), A10 Networks
B. Software Load Balancers
Software applications that run on standard operating systems and hardware:
Advantages:
- Lower cost and flexible deployment
- Can run on commodity hardware or virtualized
- Frequently updated with new features
- Often open-source options available
Limitations:
- May have lower raw performance than hardware solutions
- Depend on underlying OS and hardware
- May require more configuration expertise
Examples: NGINX, HAProxy, Apache with mod_proxy
C. Cloud Load Balancers
Managed services provided by cloud platforms:
Advantages:
- Fully managed service with minimal configuration
- Auto-scaling capabilities
- Pay-for-use pricing model
- Integrated with other cloud services
Limitations:
- Potential vendor lock-in
- Less direct control over configuration
- Costs can grow with traffic volume
Examples: AWS Elastic Load Balancing, Google Cloud Load Balancing, Azure Load Balancer
3.4 Layer 4 vs. Layer 7 Load Balancing
A. Layer 4 (Transport Layer) Load Balancing
Distributes traffic based on network information such as IP addresses and TCP/UDP ports:
Advantages:
- Lower processing overhead
- Higher throughput
- Protocol-agnostic
- Simple implementation
Limitations:
- Can't make routing decisions based on application data
- Limited flexibility for advanced request routing
- Less sophisticated health checking
B. Layer 7 (Application Layer) Load Balancing
Makes routing decisions based on application-level data like HTTP headers, cookies, or URL patterns:
Advantages:
- Intelligent content-based routing
- Can implement SSL termination
- Advanced session persistence options
- Better visibility into application health
Limitations:
- Higher processing overhead
- Lower raw throughput
- More complex configuration
- Requires understanding of application protocols
4. Building Scalable Architectures
4.1 Microservices Architecture
Breaking monolithic applications into smaller, independently deployable services facilitates scaling specific components based on their individual requirements:
Benefits for scalability:
- Independent scaling of components
- Technology diversity for optimal solutions
- Isolated failure domains
- Parallel development and deployment
Implementation considerations:
- Service discovery and registration
- Inter-service communication patterns
- Data consistency challenges
- Operational complexity
4.2 Containerization and Orchestration
Containers package applications with their dependencies, providing consistent environments across development and production:
Docker standardizes container format and runtime, while orchestration platforms like Kubernetes manage deployment, scaling, and operations of containerized applications:
Key scalability features:
- Automatic scaling based on metrics
- Self-healing capabilities
- Declarative scaling policies
- Resource optimization
4.3 Serverless Architecture
Serverless computing abstracts infrastructure management, allowing developers to focus on code while the platform handles scaling:
Advantages for scalability:
- Automatic scaling to zero when inactive
- Pay-only-for-execution pricing model
- No infrastructure management overhead
- Native support for event-driven patterns
Considerations:
- Cold start latency
- Vendor lock-in concerns
- Maximum execution time limits
- Monitoring and debugging challenges
4.4 Content Delivery Networks (CDNs)
CDNs distribute static content across geographically dispersed servers, reducing load on origin servers and improving delivery speed:
Scalability benefits:
- Offloads bandwidth-intensive content
- Reduces origin server load
- Improves global performance
- Handles traffic spikes gracefully
Implementation strategies:
- Push vs. pull content models
- Cache invalidation techniques
- Origin shielding to protect backends
- Dynamic content acceleration
5. Real-World Implementation Strategies
5.1 Auto-Scaling
Auto-scaling automatically adjusts resource capacity based on current demand:
Types:
- Reactive auto-scaling: Responds to current metrics
- Predictive auto-scaling: Anticipates demand patterns
- Schedule-based auto-scaling: Follows predetermined schedules
Implementation examples:
- AWS Auto Scaling Groups
- Kubernetes Horizontal Pod Autoscaler
- Azure VM Scale Sets
Best practices:
- Define appropriate metrics (CPU, memory, request rate, etc.)
- Set conservative thresholds to prevent oscillation
- Implement warm-up periods for new instances
- Test scaling behavior under various conditions
5.2 Global Load Balancing and Geographic Distribution
Distributing traffic across data centers or regions improves resilience and user experience:
Approaches:
- DNS-based global load balancing
- Anycast routing
- Multi-region active-active deployments
- Geolocation-based routing
Considerations:
- Data sovereignty and compliance
- Replication and consistency strategies
- Disaster recovery planning
- Traffic management during regional outages
5.3 Database Scaling Deep Dive
A. Read Replicas
Creating read-only copies of databases to distribute query load:
Implementation approaches:
- Master-slave replication
- Multi-master replication
- Cascading replication topologies
Considerations:
- Replication lag management
- Read consistency models
- Failover procedures
- Query routing logic
B. Sharding Strategies
Partitioning data across multiple database instances:
Common sharding approaches:
- Horizontal sharding: Rows distributed across shards
- Vertical sharding: Columns or features separated
- Directory-based sharding: Central lookup service for shard location
Implementation considerations:
- Shard key selection criteria
- Rebalancing strategies
- Cross-shard queries and joins
- Consistent hashing for distribution
C. NoSQL and NewSQL Solutions
Modern database systems designed for horizontal scalability:
NoSQL categories:
- Document stores (MongoDB, Couchbase)
- Key-value stores (Redis, DynamoDB)
- Column-family stores (Cassandra, HBase)
- Graph databases (Neo4j, ArangoDB)
NewSQL approaches:
- Google Spanner
- CockroachDB
- Amazon Aurora
- NuoDB
Selection criteria:
- Data model requirements
- Consistency vs. availability needs
- Query patterns and indexing
- Operational considerations
6. Monitoring and Performance Optimization
6.1 Scalability Metrics
Key indicators for measuring scalability:
- Throughput: Requests per second, transactions per second
- Response time: Average, percentiles (p95, p99)
- Resource utilization: CPU, memory, disk, network
- Concurrency: Active connections, concurrent users
- Elasticity: Time to scale, resource efficiency
6.2 Monitoring Tools and Approaches
Comprehensive monitoring is essential for scalable systems:
Tool categories:
- Infrastructure monitoring: Prometheus, Nagios, Datadog
- Application Performance Monitoring: New Relic, AppDynamics, Dynatrace
- Log management: ELK Stack, Graylog, Splunk
- Distributed tracing: Jaeger, Zipkin, AWS X-Ray
Implementation strategies:
- Unified monitoring dashboards
- Automated alerting with appropriate thresholds
- Correlation between metrics, logs, and traces
- Capacity planning based on trend analysis
6.3 Performance Testing for Scalability
Validating scalability requires systematic testing:
Testing methodologies:
- Load testing: System behavior under expected load
- Stress testing: System limits and breaking points
- Soak testing: Performance over extended periods
- Spike testing: Sudden traffic increases
Best practices:
- Test in production-like environments
- Use realistic data volumes and patterns
- Automate tests in CI/CD pipelines
- Include failure scenarios and recovery testing
7. Challenges and Considerations
7.1 Consistency vs. Availability Tradeoffs
Distributed systems must navigate the CAP theorem trade-offs:
- Consistency: All nodes see the same data at the same time
- Availability: Every request receives a response
- Partition tolerance: System continues despite network failures
Common approaches:
- Strong consistency models for critical transactions
- Eventual consistency for high availability needs
- ACID vs. BASE transaction models
- Compensating transactions for failure recovery
7.2 Cost Optimization
Scalable architectures must balance performance with financial considerations:
Optimization strategies:
- Right-sizing infrastructure components
- Reserved instances for predictable workloads
- Spot/preemptible instances for interruptible tasks
- Serverless for variable or sporadic workloads
- Multi-tier storage for cost-effective data management
7.3 Security in Scaled Environments
Scaling introduces unique security challenges:
Key considerations:
- Distributed authentication and authorization
- Secrets management across instances
- Attack surface expansion
- Compliance in multi-region deployments
- Security monitoring at scale
8. Future Trends in Scalability and Load Balancing
8.1 Edge Computing
Pushing computing closer to data sources and users:
- 5G enabling more powerful edge processing
- Specialized edge-optimized frameworks
- Hybrid edge-cloud architectures
- Local load balancing at edge locations
8.2 AI-Driven Scaling and Load Balancing
Machine learning optimizing resource allocation:
- Predictive scaling based on historical patterns
- Intelligent routing based on real-time performance
- Anomaly detection for proactive intervention
- Self-tuning load balancing algorithms
8.3 Multi-Cloud and Hybrid Architectures
Leveraging multiple infrastructure providers:
- Cross-cloud load balancing
- Cloud-agnostic deployment models
- Traffic steering based on cost and performance
- Disaster recovery across providers
9. Case Studies
9.1 Netflix: Extreme Horizontal Scaling
Netflix serves millions of concurrent video streams globally, demonstrating horizontal scaling at massive scale:
Key strategies:
- Microservices architecture with thousands of services
- Chaos Engineering to ensure resilience
- Proactive auto-scaling based on regional traffic patterns
- Multi-region active-active deployment
Lessons learned:
- Design for failure at every level
- Embrace asynchronous communication
- Test failure scenarios continuously
- Optimize for regional traffic patterns
9.2 Financial Trading Platforms: Low-Latency Scaling
Financial trading systems require both scale and ultra-low latency:
Implementation approaches:
- Specialized hardware load balancers
- In-memory data grids for state management
- Geographic distribution near financial exchanges
- Vertical scaling for critical path components
Results:
- Sub-millisecond response times at scale
- Resilience during market volatility events
- Consistent performance across trading volumes
9.3 E-commerce: Seasonal Scaling
Online retailers face extreme traffic variations during peak shopping periods:
Scaling strategies:
- Predictive scaling based on historical patterns
- Static content offloading to CDNs
- Database read replicas for query-heavy operations
- Queue-based architecture for order processing
Outcomes:
- Handling 10x normal traffic during sales events
- Maintaining transaction integrity under load
- Cost optimization during normal periods
Conclusion
Scalability and load balancing are foundational elements of modern software architecture. As applications grow in complexity and user expectations continue to rise, architects must understand and implement these concepts effectively.
By combining the right technical approaches—whether vertical scaling, horizontal distribution, or hybrid methods—with appropriate monitoring and optimization strategies, organizations can create systems that not only handle current demands but can evolve gracefully to meet future requirements.
The journey toward truly scalable systems is continuous. It requires ongoing assessment, refinement, and adaptation to new technologies and patterns. However, the investment pays dividends in reliability, user satisfaction, and business agility.